Anchoring Identity in the Kernel Requires Building at Scale
Modern infrastructure requires strong, scalable, and transparent identity mechanisms — especially for non-human actors like services, workloads, jobs, or AI agents. At Riptides, we deliver exactly that by anchoring non-human identity at the kernel level. Using technologies like SPIFFE, kTLS, and in-kernel mTLS handshakes, our platform offers zero trust security: authenticated, encrypted communication for user-space applications, without requiring developers to modify their code.
But to make this work, our system needs deep integration with the Linux kernel. We deploy custom eBPF-based telemetry and kernel modules that issue identity, track posture, and enforce policy at runtime. That means supporting a growing matrix of kernel versions, distributions, and CPU architectures — and being able to build and deliver the right driver to the right workload, at the right time.
This post walks through how we built a cloud-native, incremental kernel module build system using Docker, GitHub Actions, and EKS — one that produces hundreds of kernel-specific drivers daily, with minimal friction and full automation.
Incremental, Cloud-Native Builds for Hundreds of Kernel Versions Powered by Docker, GitHub Actions, and EKS
Building and maintaining kernel drivers for half a dozen Linux distributions and two CPU architectures is a deceptively complex task. Dependency hell, constantly changing kernel Application Binary Interfaces (ABIs), and the need for rapid vulnerability fixes turn a "simple" make && make install into a true at-scale engineering challenge. This article walks through the architecture, and inner workings of our build pipeline which is a Docker-based, GitHub Actions powered system that compiles and ships drivers to an S3 bucket across Ubuntu, Amazon Linux 2, Amazon Linux 2023, Fedora, AlmaLinux, and Debian on both x86_64 and arm64.
Challenges
Maintaining a modern kernel driver farm means satisfying three moving targets simultaneously: supported distributions, supported kernel releases within each distribution, and supported CPU architectures. Each axis amplifies matrix complexity exponentially.
- Distribution fragmentation: Different package managers, divergent header package naming conventions, and incompatible toolchains force per-distro build containers.
- Kernel cadence: Distributions such as Fedora and Ubuntu LTS publish new kernels weekly to address CVEs, so prebuilt drivers become obsolete almost overnight.
- Architecture diversity: x86_64 still dominates, but aarch64 (ARM64) is rapidly gaining traction in Graviton-powered AWS fleets and edge devices. Cross-compilation often fails because tracing hooks and CONFIG_* flags differ by arch.
A quick calculation of driver build matrix size
Even a modest 480 variant grid exceeds what can be built manually, so the automation is non-negotiable.
How the Falco Community Tackles the Problem
The Falco security project faced a nearly identical challenge compiling its kernel module and eBPF probes. Their answer combines three open-source components:
- kernel-crawler: Scrapes distro mirrors weekly, producing a JSON manifest of every kernel header package.
- dbg-go: Consumes the JSON manifest and generates driver-specific build configurations.
- prow: A Kubernetes-native CI system originally built for the Kubernetes project, orchestrating containerized build jobs at scale. Falco’s test-infra repository wires these pieces together: kernel-crawler opens a PR with new kernels; Prow detects the change, fans out parallel driverkit builds, and uploads finished artifacts.
We decided against using Prow primarily due to its configuration complexity and steep learning curve. Additionally, Prow’s terminology, such as ProwJob, Deck, Tide, and Hook is tightly coupled to its internal architecture and not immediately intuitive. This makes onboarding and day-to-day maintenance more difficult compared to alternatives that prioritize simplicity.
Our Opinionated Approach: Docker + GitHub Actions + EKS
We distilled the Falco pattern into a leaner stack that leverages tools our engineers already use daily.
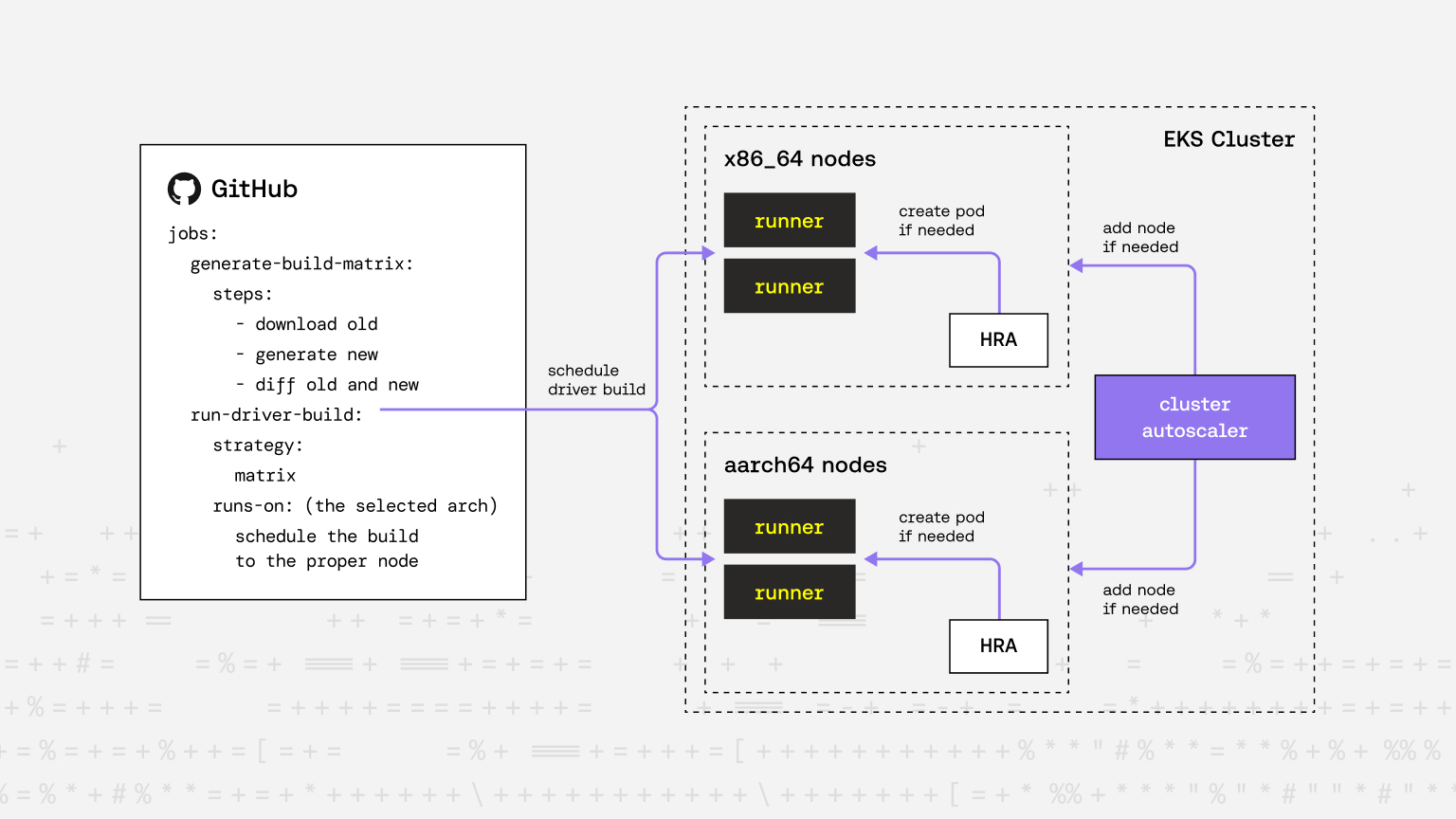
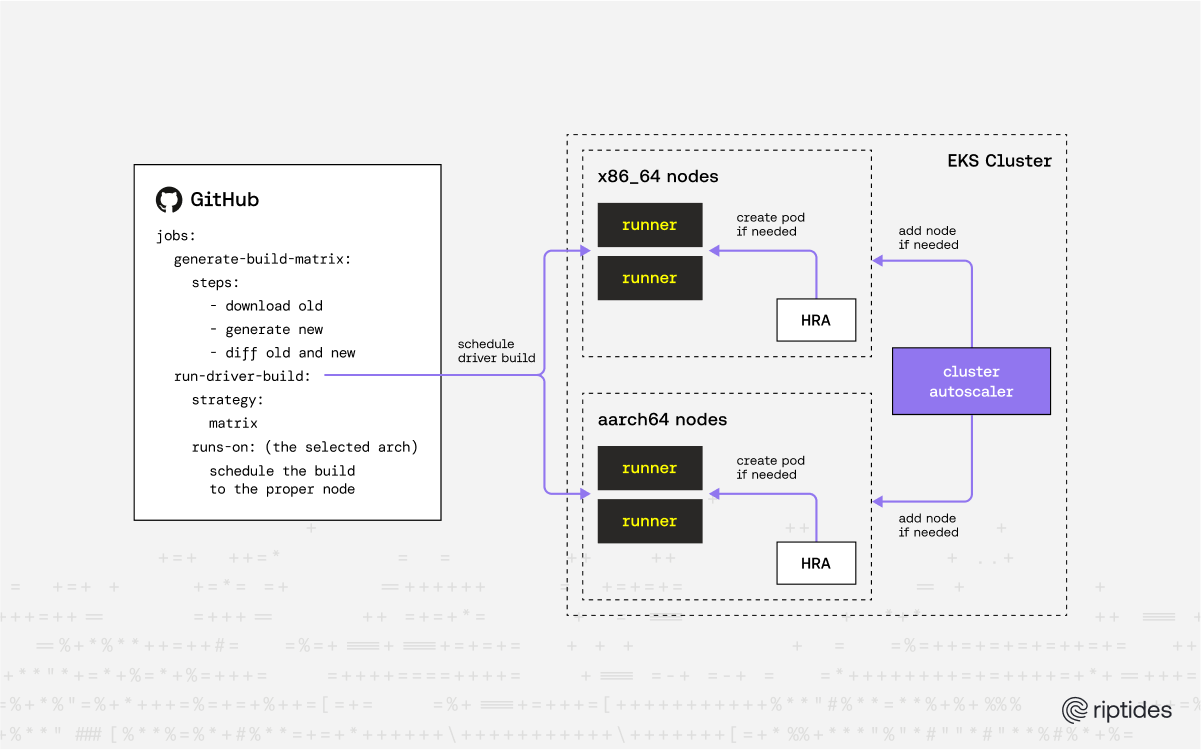
High Level Architecture:
Generating the Build Matrix
At the heart of the pipeline is our matrix-gen CLI tool that consumes Falco’s kernel-crawler JSON dataset and emits a filtered JSON tailored to our needs.
matrix-gen generate\
--distro=ubuntu,amazonlinux2,amazonlinux2023,fedora,almalinux,debian \
--arch=x86_64,aarch64 \
--driver-version=0.1.1 \
--kernel-release='.*6\.[0-9]+\..*'
Sample Output Element
[
{
"kversion": "6.1.12-17.42.amzn2023.x86_64",
"distribution": "amazonlinux2023",
"architecture": "x86_64",
"kernelurls": [
"https://amazonlinux-2023-repos.s3.us-west-2.amazonaws.com/2023.0.20231016.0/kernel/6.1.12-17.42.amzn2023.x86_64/kernel-6.1.12-17.42.amzn2023.x86_64.rpm"
],
"output": "0.1.0/amazonlinux2023/x86_64/6.1.12-17.42.amzn2023.x86_64",
"driverversion": "0.1.1"
},
...
]
Key fields:
- kernelurls: Direct links to header RPM/DEB packages, used when distro mirrors purge older kernels.
- output: S3 key prefix (patch versions does not change the path in the output).
- driverversion: Semantic version baked into the built .ko files.
Matrix Diffs: Building Only What Changed
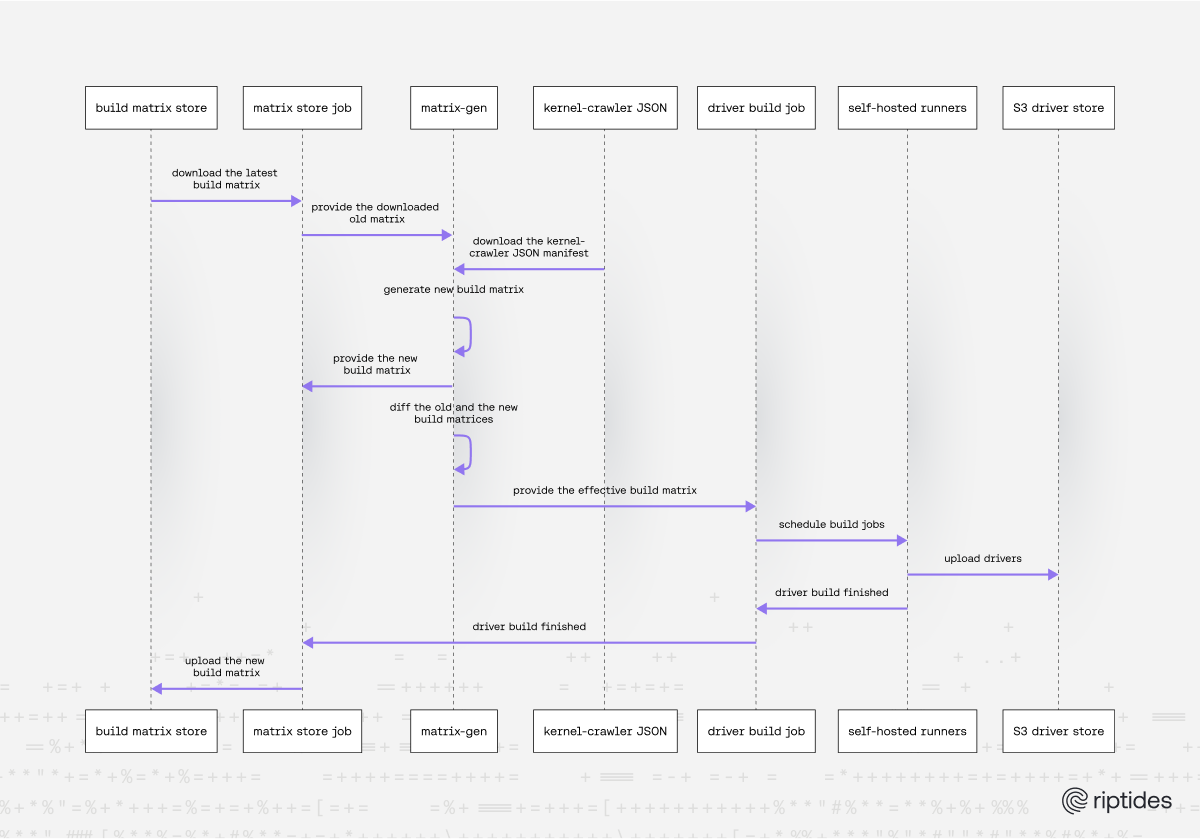
Each nightly GitHub Actions workflow takes three steps:
- Download previous matrix from S3.
- Regenerate a fresh matrix with matrix-gen.
- Smart diff the JSON files. The matrix-gen CLI includes a dedicated diff subcommand, so it computes the delta between the previously published matrix and the freshly generated one. Only new or modified entries feed the build matrix.
This approach shrinks CI time drastically. If just two new Fedora kernels land overnight, the workflow launches only two jobs instead of rebuilding hundreds. When we release a driver patch, the diff naturally marks every entry as changed, ensuring all variants are rebuilt with fixes.
Containerized Build Execution with Elastic Infrastructure
After the build matrix is generated, we rely on three key pillars to make our driver builds fast, simple, and reproducible.
1. Docker-Based Build Jobs
We maintain a directory of slim, distro-specific Dockerfiles that have common characteristics:
- Mirror install first (apt-get install linux-headers-${kversion} style). If that fails, fall back to the explicit kernelurls defined by the matrix.
- ENTRYPOINT is a shared shell script that runs the driver build, and copies bearssl.ko + riptides.ko into /output.
2. Architecture-Aware Scheduling
Each matrix element carries an 'architecture' field. GitHub Actions assigns a runs-on: [self-hosted, build, x86_64] or [self-hosted, build, aarch64] label dynamically, ensuring ARC schedules the pod on a node with the matching CPU.
3. Runner & Node Autoscaling
Actions Runner Controller (ARC)’s RunnerDeployment objects declare how many idle runners should persist. HorizontalRunnerAutoscaler (HRA) adjusts replicas using Live Job Queue metrics. Meanwhile, the Kubernetes Cluster Autoscaler on EKS grows or shrinks EC2 nodes based on pending pods, giving us a two-tier elasticity model:
- Inner loop: HRA scales runners (pods) from 1 → N based on demand.
- Outer loop: Cluster Autoscaler provisions new nodes if the pod-level scale-up cannot fit. The result: cost-effective builds that spin up on demand and disappear minutes after completion.
Sequence Diagram of Driver Build:
Future Evolution: RunnerScaleSets
A Runner Scale Set is a managed group of self-hosted GitHub Actions runners that can automatically scale up or down based on job demand.
Key Advantages of RunnerScaleSet Over HorizontalRunnerAutoscaler:
- No Secrets in Runner Pods: Authentication is handled at the controller, so sensitive tokens aren’t injected into each runner, improving security.
- Fewer GitHub API Calls: Scale Sets use efficient long-polling connections, reducing API rate-limit issues common with HorizontalRunnerAutoscaler.
- More Reliable and Responsive Scaling: Direct 'job available' signals from GitHub provide faster, more accurate scaling, including robust scale-to-zero.
- Advanced Features: Improved runner pod customization and better support for large-scale or multi-repo environments
- Reduced Operational Overhead: Fewer moving parts make management and upgrades easier.
RunnerScaleSets are more secure, efficient, and easier to manage compared to HorizontalRunnerAutoscaler.
Conclusion
By integrating open-source tools like kernel-crawler, leveraging containerized builds, and deploying a cloud-native CI/CD pipeline with elastic scaling, we turned a notoriously brittle part of kernel engineering into a reliable, automated system. The result is a scalable driver build infrastructure that keeps pace with upstream kernel releases, supports a diverse range of environments, and requires minimal human intervention. This investment is foundational. The telemetry and enforcement capabilities that set Riptides apart begin with kernel-level visibility. And that visibility depends on having the right module, built for the right kernel, shipped to the right place — every time. With this system in place and upcoming migration to GitHub Runner Scale Sets, we're ready to scale even further, simplify operations, and continue delivering on our mission to secure workloads from the kernel up.
Key takeaways:
- Use the existing data to save time by leveraging collected kernel-crawler JSON instead of scraping distribution mirrors yourself.
- Diff your matrix to keep nightly builds incremental.
- Leverage two-layer autoscaling ARC for runners, Cluster Autoscaler for nodes (both speed and cost control).
- Keep Dockerfiles declarative and immutable, fallback URLs shield you from mirror churn.
This setup meets today’s scale comfortably, and with upcoming RunnerScaleSets we expect even smoother scaling and simpler secrets management.
Ready to replace secrets
with trusted identities?
Build with trust at the core.
