Why SPIFFE Is Non-Negotiable for Agent Identity — and Why SPIRE Was Never Built to Deliver It
If you’re building or operating AI agents in production, you already know the identity problem is real. Your agent connects to MCP servers, calls external APIs, handles OAuth tokens, and chains tools together, all autonomously. Every one of those interactions needs authentication. Every one of those interactions is a credential that can be stolen.
SPIFFE solves the identity part. It gives your agent a cryptographically verifiable identity — an SVID — that’s ephemeral, rotatable, and doesn’t rely on static secrets. That’s exactly what agents need. But how you deliver that SPIFFE identity, and what you do with it after issuance, matters more than most people realize. And if you’re reaching for SPIRE — SPIFFE’s reference implementation — you’re about to hit walls on both fronts.
Note: There are two distinct identity problems when you run AI agents in production. The first is the agent’s own identity — a non-human, workload-level identity that proves which process is making a request. That’s what SPIFFE solves. The second is the user’s identity — the human on whose behalf the agent is acting. When your agent calls an MCP server or a cloud API, it needs a credential that represents the user’s authorization, not just its own. These are separate trust relationships and they need separate mechanisms: SPIFFE SVIDs for the agent, OAuth/delegated credentials for the user, both managed without secrets ever touching the agent’s memory. For further reference check out or latest post on the topic, Securing Agentic OAuth Flows with Riptides.
SPIRE: A Reference Implementation, Not a Security Platform
Before we talk about agents, let’s be precise about what SPIRE is and isn’t.
SPIFFE is a specification. It defines the identity model — SPIFFE IDs, SVIDs, trust domains — but says nothing about how those identities should be issued, enforced, or operationalized. SPIRE is the CNCF reference implementation of that spec. It was built to demonstrate that the SPIFFE model works: run a server, deploy node agents, attest workloads, issue SVIDs. And for that purpose, it succeeded. SPIRE brought SPIFFE to the mainstream and proved that workload identity at scale is achievable.
But a reference implementation is designed to prove the spec works — not to be the production security platform you build on. The next question is: what does a purpose-built delivery mechanism look like, one that handles not just identity issuance, but policy, rotation, posture, and credential lifecycle as a single system?
Even in traditional infrastructure — long before AI agents entered the picture — SPIRE leaves significant operational gaps that teams have to fill themselves:
Certificate lifecycle is the operator’s problem. SPIRE issues certificates, but what happens next is on you. Rotation logic has to be handled by the workload or its sidecar. If a certificate expires because the renewal failed or the agent was unreachable, the workload loses its identity. There’s no built-in fallback, no automatic recovery, no centralized lifecycle management. At scale, this turns into an operational burden that grows with every workload you onboard.
No access policy enforcement. SPIRE tells you who a workload is. It doesn’t tell you what that workload is allowed to do. There is no policy engine, no authorization layer, no way to express “workload A can talk to service B on port 443 but not service C.” Policy enforcement is left entirely to external systems — service meshes, OPA sidecars, application-level checks. The gap between “identity issued” and “access controlled” is filled by other tools, other configurations, and other failure modes.
No posture management. SPIRE attests a workload at registration time. But what happens if the workload’s binary changes after attestation? If its environment drifts? If its runtime characteristics no longer match the security posture you expect? SPIRE doesn’t continuously verify. It doesn’t re-attest. Once the SVID is issued, the workload is trusted for the duration of that certificate’s validity, regardless of what it becomes.
No credential management beyond SVIDs. Workloads don’t just need SPIFFE identities. They need OAuth tokens, cloud provider credentials, API keys, database passwords. SPIRE has no mechanism for managing, injecting, or rotating these credentials. That entire surface area — which is where most real-world authentication happens — falls outside SPIRE’s scope.
Secrets live in user space. SPIRE delivers SVIDs to workloads through a gRPC Workload API, typically via a Unix domain socket. The workload (or its proxy) loads the certificate and private key into its own process memory. From that point forward, the private key is in user space — accessible to the process, to any exploit that achieves code execution in that context.
These aren’t edge cases. They’re the everyday reality of operating SPIRE at scale. And they exist before you introduce the complexity of AI agents.
Now Add AI Agents — and SPIRE’s Model Breaks Down Further
If SPIRE already struggles as a complete security solution for traditional workloads, the AI agent world makes every limitation worse.
Agents are polyglot and framework-diverse. Your agent might be a Python script using LangChain, a TypeScript process running on Vercel, a Go binary orchestrating sub-agents, or Claude Code running from a terminal. SPIRE’s Workload API requires the workload to participate — to call the API, load the certificate, and manage the TLS connection. That means code changes. That means language-specific libraries. In the agent ecosystem, where frameworks evolve weekly and there is no stable integration point, this is a non-starter.
Agents are ephemeral and spawn dynamically. An agent orchestrator might spin up sub-agents on demand to handle tool calls, delegate context expansion, or parallelize tasks. SPIRE requires that every workload be pre-registered with the SPIRE server — a registration entry mapping a SPIFFE ID to a set of selectors — before the workload can be attested and issued an SVID. For dynamic sub-agents that are created on the fly, this means either pre-registering every possible agent variant ahead of time or building an external automation pipeline that races to create registration entries as processes spawn. On top of that, SPIRE’s attestation is pull-based: the workload itself must actively call the Workload API over a Unix domain socket to request its SVID. A sub-agent that doesn’t integrate the SPIRE SDK or client library simply never gets an identity. For short-lived processes, the overhead of calling the API, receiving the SVID, configuring TLS, and then performing actual work may outweigh the process’s entire useful lifetime.
Agents don’t live exclusively in Kubernetes. Many agent deployments run on VMs, bare-metal dev boxes, edge nodes, or as local CLI tools. SPIRE’s operational model leans heavily on Kubernetes primitives for workload registration, sidecar injection, and service account-based attestation. If your agent runs outside Kubernetes — and many do — you’re fighting the deployment model, not leveraging it.
Agents chain tools across trust boundaries. A single agent session might hit a Cloudflare MCP server, call an AWS Bedrock endpoint, query a GCP Vertex API, and write to an internal database. Each hop requires a different credential type. SPIRE issues SVIDs, but the agent still needs to exchange those SVIDs for OAuth tokens, AWS SigV4 signatures, or GCP access tokens. That exchange logic has to live somewhere, and in SPIRE’s model, it lives in your code or in yet another sidecar.
The Sidecar Trap
If you can’t embed the SPIFFE logic in the agent, the next move is usually a sidecar or proxy — Envoy with SDS, a custom mTLS proxy, or a service mesh that handles certificate rotation and TLS termination on the agent’s behalf.
Here’s why it falls apart for agents:
Identity confusion. When a sidecar proxy handles TLS, the SVID belongs to the proxy process, not the agent process. The MCP server on the other end sees the proxy’s identity, not the agent’s. If two agents share a node and a proxy, the identity fidelity degrades further. You’ve introduced a layer of indirection between “who is making this request” and “who authenticated this request.” In the agent world, where processes are dynamic and potentially untrusted — think prompt injection leading to rogue tool calls — this ambiguity is a security gap.
Operational weight. Every agent process now needs a companion proxy. That’s double the processes, double the memory, double the failure modes. For a team running hundreds of agent instances across mixed infrastructure, this overhead is a real operational and cost burden.
Deployment coupling. Sidecar injection in Kubernetes is well-understood. Sidecar injection on a developer’s laptop, a VM running Claude Code, or an edge device running a local agent? That’s a custom problem every time.
The credential problem doesn’t go away. Even with a sidecar handling mTLS, the agent still needs to manage OAuth access tokens, API keys, and session credentials for third-party services. The sidecar terminates TLS but it doesn’t solve the credential lifecycle problem. Tokens still end up in the agent’s memory, in environment variables, in config files — plaintext, replayable, and one prompt injection away from exfiltration.
What Agents Actually Need
Let’s reframe the requirements from the ground up.
An AI agent needs a cryptographic identity that is bound to its process — not to a pod, not to a node, not to a proxy sitting next to it. That identity needs to be issued automatically when the process starts, rotated transparently, and revoked when the process ends. The agent code should not need to know about SPIFFE, SVIDs, certificate rotation, or TLS handshakes.
But identity alone is not enough. The agent also needs access policies that govern which services it can reach and under what conditions. It needs continuous posture verification — not just a one-time attestation at boot, but ongoing validation that the agent process is what it claims to be. It needs credential management for every external service it touches — OAuth tokens, cloud credentials, API keys — without those credentials ever landing in the agent’s memory. And it needs all of this managed centrally, rotated automatically, and enforced at a layer the agent can’t tamper with.
SPIRE delivers the first piece — identity issuance — and leaves the rest to you. That’s not a security solution. That’s a starting point.
The Kernel as the Identity and Enforcement Plane
There’s one layer that every agent process touches, regardless of language, framework, deployment model, or orchestrator: the Linux kernel. Every connect() syscall, every socket opened, every TCP handshake — it all goes through the kernel. That makes the kernel the natural enforcement point for workload identity, access policy, and credential management.
This is the approach Riptides takes. But it’s important to understand what Riptides is and isn’t: Riptides is not just a SPIFFE provider. We use and love SPIFFE as the identity standard — it’s the right abstraction, and we issue SPIFFE-compliant SVIDs. But identity issuance is the foundation, not the product. What Riptides delivers is a complete security platform built on top of that foundation.
Identity: SPIFFE in the Kernel
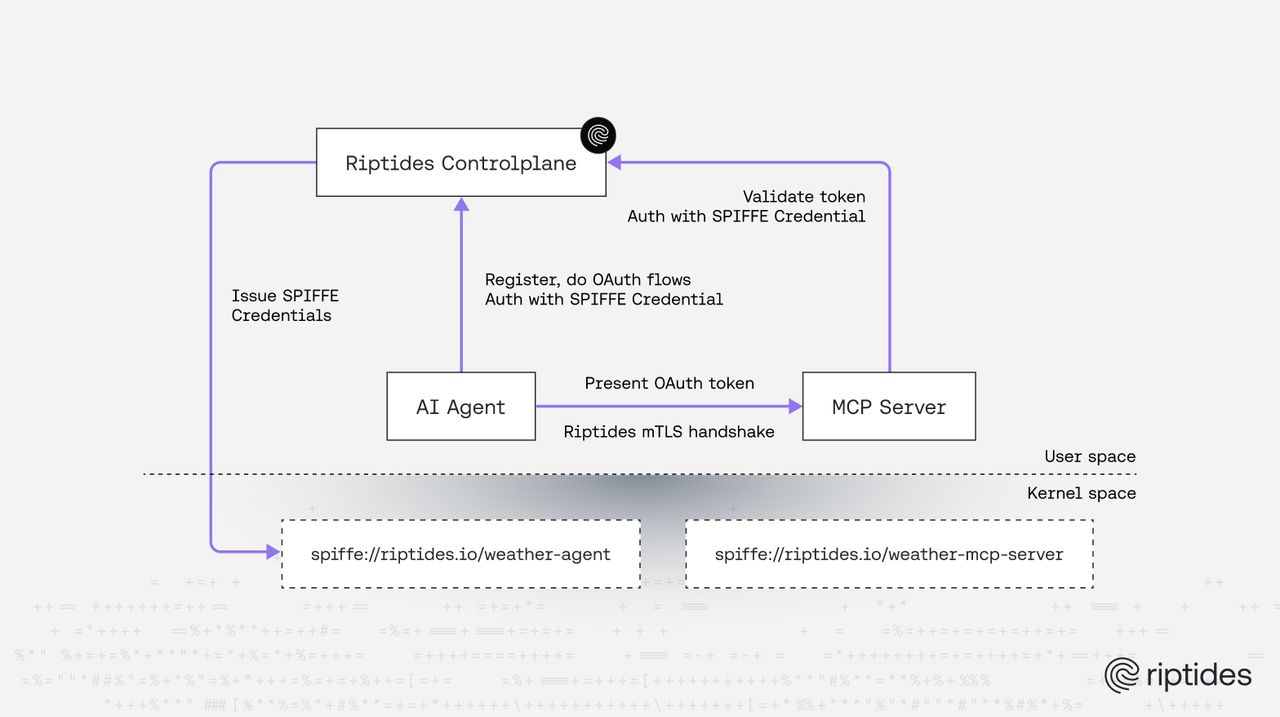
Riptides issues SPIFFE-compliant X.509 certificates directly inside the Linux kernel, bound to the actual process initiating communication. Using kernel TLS (kTLS), the SVID is injected into the TLS handshake at the record layer. The application — your agent — doesn’t participate. It doesn’t load certificates. It doesn’t call a Workload API. It just opens a connection, and the kernel handles the rest.
Per-process identity binding. The identity is tied to the specific process, identified at the syscall level. Not to a pod, not to a node, not to a proxy. If an agent spawns a sub-process, that sub-process gets its own identity based on its own attestation. If a rogue process tries to impersonate an agent, it can’t — the kernel module verifies process attributes before injecting any credential.
Zero code changes. Your Python LangChain agent, your TypeScript MCP client, your Go orchestrator, Claude Code — none of them need to know about SPIFFE. There are no SDKs to embed, no libraries to import, no gRPC calls to make.
No secrets in user space. Private keys never leave kernel memory. SVIDs are not written to disk, not exposed via filesystem mounts, not passed through environment variables.
Works everywhere Linux runs. Kubernetes, VMs, bare metal, developer workstations, edge devices. The deployment model is the same everywhere.
Automatic Certificate Lifecycle
Unlike SPIRE, where rotation is the workload’s responsibility, Riptides manages the entire certificate lifecycle from the control plane. Certificates are issued, rotated, and revoked automatically. The agent process never participates in renewal. There are no expiration windows to race against, no renewal failures to debug, no zombie workloads running with stale certificates. The control plane tracks certificate state, and the kernel module receives updated credentials through a secure channel — transparently, continuously, without downtime.
Access Policy Enforcement
Riptides doesn’t just tell you who a workload is. It controls what that workload can do. Access policies are defined centrally and enforced at the kernel level, at connection time. When an agent process opens a socket to a destination, the kernel module checks the agent’s identity against the configured policy before the connection is established. If the policy says this agent can’t reach that service, the connection is denied — not by a proxy, not by a sidecar, not by an application-level check, but by the kernel itself. This is enforcement that the agent process cannot bypass, cannot misconfigure, and cannot be prompted into circumventing.
Continuous Posture Management
Riptides doesn’t attest a workload once and trust it forever. The attestation pipeline continuously collects process-level evidence — binary hashes, environment metadata, runtime characteristics, node posture — and validates it against expected baselines. If an agent’s posture drifts — if its binary changes, if its environment is tampered with, if its runtime behavior deviates — its identity can be revoked or its access restricted in real time. In the age of AI agents, where prompt injection can alter an agent’s behavior without changing its process signature, continuous posture verification is not optional. It’s the difference between “this process was trustworthy when it started” and “this process is trustworthy right now.”
Secretless Credential Injection
Here’s where the kernel-based model goes beyond anything SPIRE or sidecar architectures can offer.
When your agent connects to a remote MCP server that requires OAuth, it goes through a standard OAuth2 authorization code flow. But with Riptides, the agent never holds the real access token. Instead, Riptides acts as an intermediate authorization server, brokers the real OAuth flow on the agent’s behalf, stores the actual access token in the kernel, and issues the agent a Riptides JWT — a transient credential that is meaningless outside the system.
When the agent sends a request to the MCP server with that JWT in the Authorization header, the kernel module intercepts the outgoing request, verifies the process identity matches, looks up the real credential, and swaps the JWT for the actual access token before the packet leaves the machine. The MCP server sees a fully authenticated request. The agent never possessed the credential that made it possible.
This same pattern applies to AWS credentials, GCP tokens, Azure service principal secrets, and any other credential type. The kernel module does the swap on the wire. The agent operates in a secretless model — it authenticates, it participates in authorization flows, but it never holds the keys to the kingdom.
An agent that can be prompted into exfiltrating its own credentials cannot exfiltrate credentials it does not have.
The Full Picture: SPIRE vs. Riptides for AI Agents
| Capability | SPIRE | Riptides |
|---|---|---|
| SPIFFE identity issuance | Yes (user space) | Yes (kernel space) |
| Zero code changes | No (Workload API or sidecar required) | Yes |
| Per-process identity binding | Limited (at SVID issuance time) | Yes (continuous, syscall-level) |
| Automatic certificate rotation | Partial (workload must participate) | Full (kernel + control plane) |
| Access policy enforcement | No (external tools required) | Yes (kernel-level, per-connection) |
| Continuous posture management | No | Yes |
| Credential injection (OAuth, cloud, API keys) | No | Yes (on-the-wire, kernel-level) |
| Secrets in user space | Yes | No |
| Works outside Kubernetes | Limited | Yes (anywhere Linux runs) |
| Agent framework agnostic | No | Yes |
SPIRE is a reference implementation that demonstrates SPIFFE identity issuance. Riptides is a security platform that uses SPIFFE as its identity foundation and builds everything else — policy, posture, credential management, and enforcement — on top of it, at the kernel level.
What This Looks Like in Practice
From an operator’s perspective, this is what’s happening:
- The agent starts. No code changes.
- Riptides assigns a verified runtime identity to the process.
- The agent connects to an external service (for example an MCP server).
- OAuth happens on behalf of the user, without exposing tokens to the agent.
- Every connection is verified and enforced at runtime.
- Certificates rotate without intervention.
- Posture is verified continuously.
No sidecars. No SDKs. No credentials in application space.
The Bottom Line
SPIFFE is the right identity standard for AI agents. It’s ephemeral, cryptographic, and doesn’t rely on static secrets — exactly what you need for autonomous workloads that spawn dynamically and chain tools across trust boundaries.
But SPIRE — the reference implementation — was never designed to be a complete security solution, even for traditional workloads. It issues identities and leaves everything else — policy, rotation, posture, credential management, enforcement — to the operator. For AI agents, where the workload is polyglot, ephemeral, framework-diverse, and operating across trust boundaries, SPIRE’s operational model doesn’t just fall short. It doesn’t apply.
What agents need is not a better SPIFFE provider. They need a security platform that uses SPIFFE as the identity foundation and builds policy enforcement, continuous attestation, automatic credential lifecycle, and secretless credential injection on top of it — at a layer the agent cannot bypass and does not need to know about.
That layer is the kernel. And that platform is Riptides.
If you want to see kernel-level agent identity in action, get in touch for a demo. Follow us on LinkedIn and X for more.
How exposed are your workloads?
Run the NHI Security Audit Checklist, 8 questions to map your credential exposure, attribution gaps, and lateral movement surface across your own environment. Takes about 15 minutes.
Run the ChecklistFollow us on LinkedIn and X for more updates.