On-Demand Driver Builds: How We Replaced Speculative Kernel Builds with a Demand-Driven Pipeline
From Speculative Builds to Just-in-Time Kernel Coverage
In our previous posts — Building Linux Driver at Scale and Beyond the Limits — we described how we compile kernel drivers nightly for a matrix of distributions, architectures, and kernel versions. The current batch covers roughly 540 variants across Ubuntu, Amazon Linux, Fedora, Debian, and CentOS, on both x86_64 and aarch64.
That covers the common case well. The nightly run picks up new kernels from Falco’s kernel-crawler, generates a diff against the previously built set, and rebuilds only what changed.
But coverage has a natural ceiling.
Cloud providers push live-patched kernels on their own schedule. Customers run specific distribution versions that diverge from our pinned defaults. New distribution releases land between our index updates. The long tail of kernel variants a real fleet encounters is essentially unbounded.
When a Riptides node boots and its kernel driver is not in the prebuilt set, the Riptides daemon needs to work now, not at the next nightly run. We needed a way to trigger a build for exactly the right kernel, on demand, and have the result ready within minutes.
The Build Service
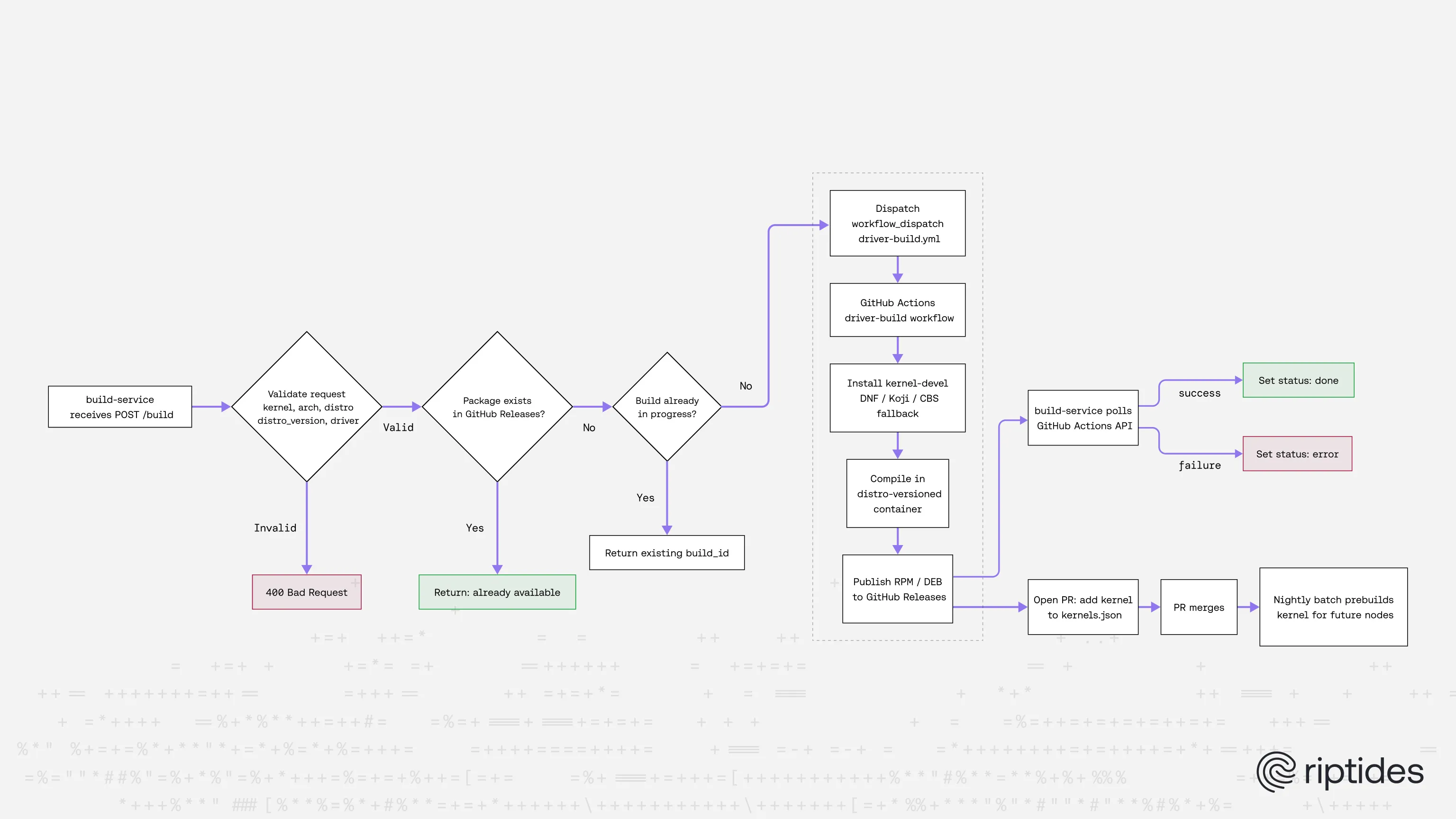
The solution is a lightweight Go HTTP service — the build-service — that sits between the Riptides driver-loader and the GitHub Actions build pipeline.
The API is intentionally minimal:
| Endpoint | Description |
|---|---|
POST /build | Trigger a driver build |
GET /status/{id} | Poll build status |
GET /healthz | Health check |
A build request carries exactly what the compiler needs:
{
"kernel_version": "6.12.58-82.121.amzn2023.x86_64",
"architecture": "x86_64",
"distribution": "amazonlinux",
"distro_version": "2023",
"driver_version": "v0.5.16"
}Before doing anything, the service checks whether the package already exists in GitHub Releases. If it does, the response is immediate with no workflow dispatch needed. If it does not, the service validates the request — checking the kernel version format, architecture, distribution, and distro version — then fires a workflow_dispatch event to the driver-build.yml GitHub Actions workflow with the exact inputs needed.
The caller gets back a build ID and polls /status/{id} until the state transitions to done or error.
{"message": "workflow dispatched", "build_id": "a3f92b1c"}$ curl /status/a3f92b1c
{"status": "in_progress"}
$ curl /status/a3f92b1c
{"status": "done"}Under the hood, the service polls the GitHub Actions API every 15 seconds to find the workflow run that was dispatched after a given timestamp, then monitors it until completion. The maximum wait is 15 minutes before the build is marked as timed out.
The service also deduplicates concurrent requests — if two nodes boot on the same new kernel simultaneously, only one workflow is dispatched and both callers receive the same build ID to poll.
Driver Distribution: RPM and DEB Packages
Every build produces a native package for the target distribution — a .deb for Debian-based distros and an .rpm for RPM-based ones — published to GitHub Releases. The package name encodes everything needed to locate the right artifact:
riptides-driver-ubuntu-6.14.0-1021-gcp_v0.1.2_amd64.deb
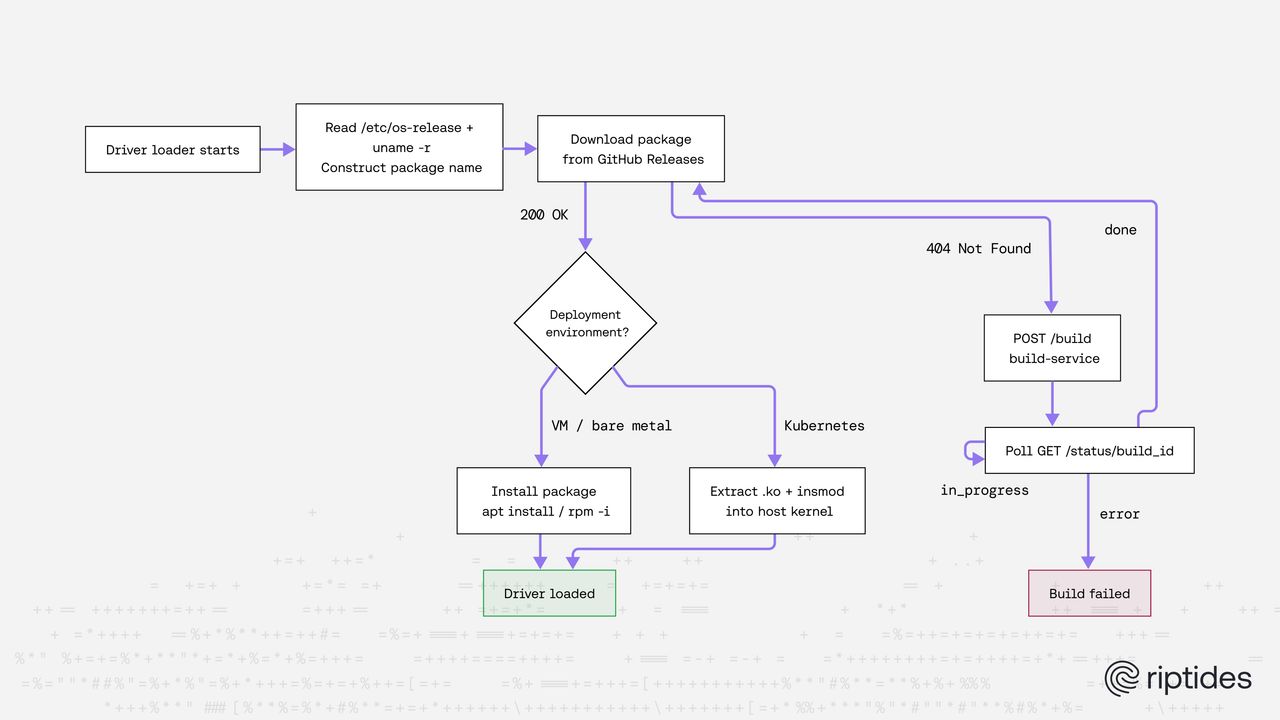
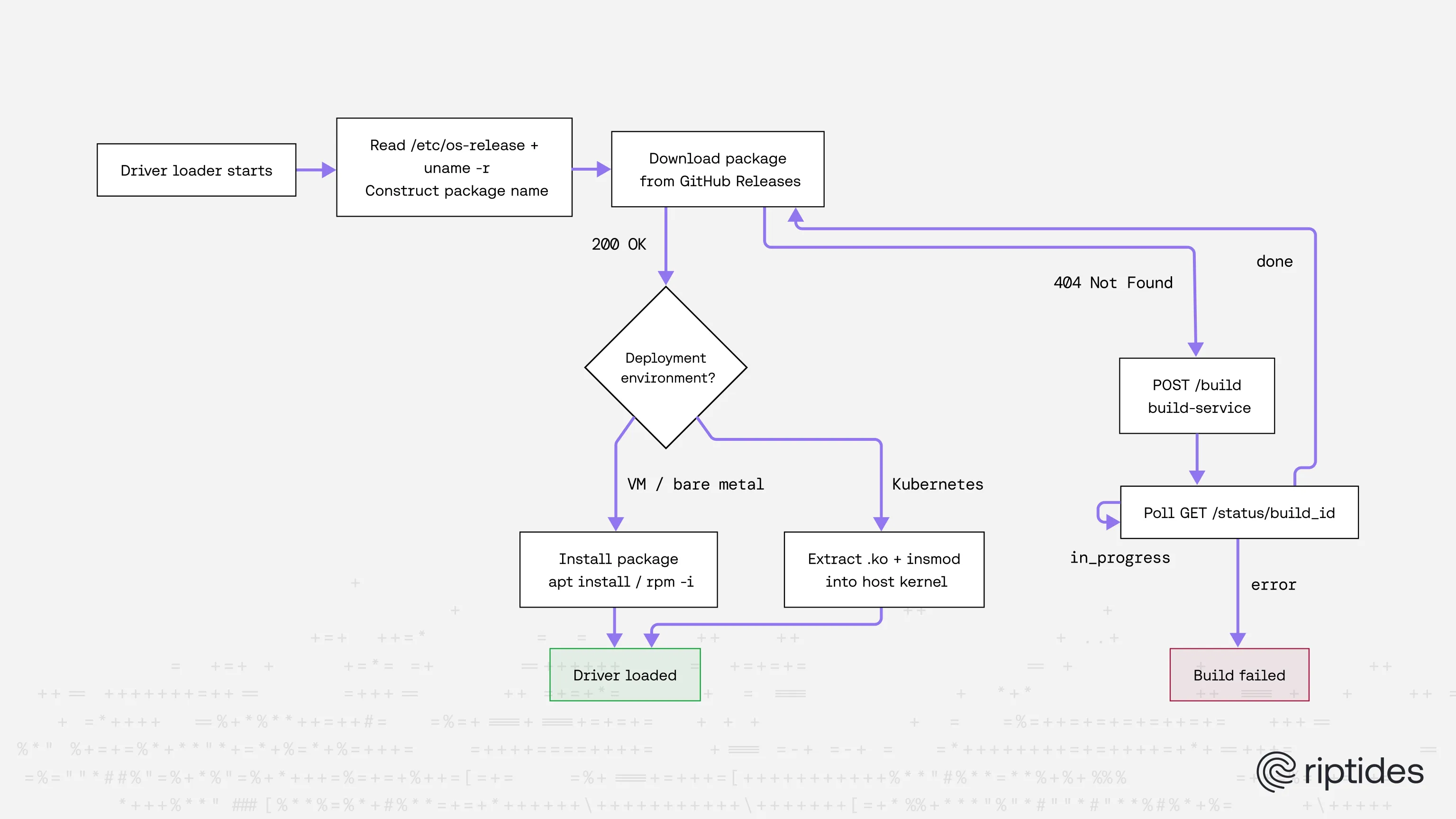
riptides-driver-amazonlinux-6.12.58-82.121.amzn2023.x86_64_v0.1.2_amd64.rpmIn both deployment environments the driver-loader follows the same flow: read /etc/os-release and uname -r to identify the exact distribution, version, and kernel, construct the package name, and attempt to download it from GitHub Releases. If the download succeeds, it proceeds to load the driver. If the response is a 404 — the package has not been built yet — it calls the build-service, waits for the build to complete, then downloads and loads the result.
How the package is loaded once downloaded differs by environment.
VM and bare metal — the driver-loader runs as a systemd service on the host and installs the Riptides driver package directly with the system package manager.
Kubernetes — the driver-loader runs as a privileged container but the kernel module must be loaded into the host kernel. Rather than installing the package on the host and risking package manager conflicts, the driver-loader extracts the .ko files from the package inside the container and uses insmod to load them directly into the host kernel.
This unified package-based approach means the same build artifact works across all deployment models — no separate paths for binary blobs, no per-environment build variants.
Filling the Gaps: Koji Fallbacks and Livepatch Discovery
Whether a build is triggered on demand or by the nightly batch, two specific gaps keep showing up in practice when compiling drivers for certain distributions.
Fedora and CentOS Stream: Koji Fallbacks
RPM-based distribution mirrors are deliberately shallow. Older kernel-devel packages age out quickly, and the standard DNF repositories often do not carry the version actually running on a customer’s node.
For Fedora, the answer is Fedora Koji — the official Fedora build system that retains packages long after they leave the standard mirrors. CentOS Stream has its own equivalent: the CentOS Build Service (CBS).
The build script detects which distribution it is running on and selects the right Koji profile automatically:
KOJI_PROFILE="koji" # Fedora Koji by default
if [[ "$ID" == "centos" ]]; then
KOJI_PROFILE="cbs"
cat > /etc/koji.conf.d/cbs.conf <<'EOF'
[cbs]
server = https://kojihub.stream.centos.org/kojihub
weburl = https://kojihub.stream.centos.org/koji
topurl = https://kojihub.stream.centos.org/kojifiles
EOF
fi
koji --profile="$KOJI_PROFILE" download-build \
--arch="$ARCH" --arch=noarch --rpm \
"${KERNEL_DEVEL_PACKAGE}-${KERNEL_VERSION}"The fallback chain for any RPM-based distribution is: DNF repo → explicit kernel URLs → Koji/CBS. This means we can build for Fedora and CentOS Stream kernel versions that have rolled off the standard mirrors without maintaining our own package mirror.
Amazon Linux: Livepatch Kernels
Amazon Linux 2023 ships live-patched kernels through a separate CDN repository (kernel-livepatch-repo-cdn). These kernels never appear in Falco’s kernel-crawler data because they are not published through the standard package mirrors that kernel-crawler scrapes.
In practice, livepatch kernels are handled naturally by the on-demand path — when a node running a livepatch kernel boots and requests a build, the driver-loader triggers the build-service and the result lands in kernels.json like any other kernel. No special discovery step is needed for the default flow.
For the optional kernel-crawler mode however, livepatch kernels would be silently missed. To close that gap, we added a discovery step that queries the livepatch CDN repository directly and merges the results into the kernel-crawler data before generating the build matrix. On the build side, the Amazon Linux Dockerfile also handles the livepatch install path — if the standard kernel-devel RPM is not available, the build script falls back to installing the matching kernel-livepatch package instead.
Distro Versioning Done Right
“Ubuntu” is not enough information to build a kernel module. You can technically compile a driver for an Ubuntu 22.04 kernel inside an Ubuntu 24.04 container — the build may succeed — but the default toolchain version differs between distro releases. That mismatch can cause subtle driver load errors at runtime because the compiler embeds version-specific metadata into the module. Pinning an exact toolchain version for every distro version combination is fragile and hard to maintain.
The simpler solution is to just build on the same distro and version as the target. A driver destined for an Ubuntu 22.04 host gets compiled in an Ubuntu 22.04 container. The toolchain matches by construction.
To make that work end to end, we pass distro_version through the entire pipeline: from the build-service request, through the GitHub Actions workflow inputs, into the Docker build arguments, and into the artifact cache key. This way the build environment is always correctly aligned with the target, and different versions of the same distribution are treated as distinct build variants rather than being conflated.
The distro_version field is optional in the request. If omitted, the service uses the pinned default per distribution (e.g., 24.04 for Ubuntu). The build container then pulls the matching prebuilt base image from our GHCR registry:
BASE_IMAGE=ghcr.io/riptideslabs/${distribution}:${version}The build cache key also includes the distro version so that concurrent builds for ubuntu:22.04 and ubuntu:24.04 with the same kernel version are treated as distinct builds rather than deduplicated:
func buildCacheKey(req BuildRequest) string {
return fmt.Sprintf("%s:%s:%s:%s:%s",
req.KernelVersion, req.Architecture,
req.Distribution, req.DistroVersion,
req.DriverVersion)
}In the default kernels.json mode this is straightforward — the distroversion field is already recorded in the file by the on-demand build, so the matrix generator reads it directly. When kernel-crawler mode is used instead, the raw kernel-crawler data does not carry an explicit distro version. In that case matrix-gen derives it from the kernel release string itself, since the version is encoded there by convention:
| Distribution | Pattern in kernel release | Example |
|---|---|---|
| Fedora | .fcXX. | 6.14.0-100.fc42.x86_64 → 42 |
| CentOS | .elXX | 6.12.0-212.el10.x86_64 → stream10 |
| Debian | ~bpoXX+ | 6.1.0-28~bpo12+1 → 12 |
| Amazon Linux | target name suffix | amazonlinux2023 → 2023 |
This way the kernel-crawler path produces correctly versioned build entries without any manual annotation, consistent with what the on-demand path records explicitly in kernels.json.
Custom Base Images
The nightly batch was already using prebuilt base image tarballs to avoid registry rate limits during large parallel runs, as described in our previous post. On-demand builds raised the same issue in a different form: sporadic single-kernel builds were still pulling from public registries, and those pulls were slow and occasionally throttled.
We extended the base image strategy to cover all distributions and versions used in on-demand builds. Each base image is built from a versioned Dockerfile.base.{distro} and pushed to GHCR. The base images are rebuilt on a weekly cron (0 2 * * 1) and on manual trigger. Every distro/version combination we support has a corresponding base image:
| Distribution | Versions |
|---|---|
| Ubuntu | 22.04, 24.04, 25.10, 26.04 |
| Debian | 12, 13 |
| Fedora | 42, 43 |
| CentOS | stream9, stream10 |
| Amazon Linux | 2023 |
The base images include all compiler toolchain dependencies pre-installed — build-essential or gcc/make equivalents, kernel header tools, OpenSSL, elfutils, TPM tools, and anything else the driver compilation requires. The per-kernel Dockerfiles now just pull from the prebuilt base and install the target kernel headers on top:
ARG DISTRO_VERSION=24.04
FROM ghcr.io/riptideslabs/ubuntu:${DISTRO_VERSION}
ARG KVERSION
ENV KVERSION=${KVERSION}
# kernel header install + driver build onlyThis eliminates the per-build package installation that previously happened inside each worker container, cutting several minutes off individual build startup time. For on-demand builds that matters directly: the driver-loader is blocked waiting for the build to complete before it can load the driver and the node becomes fully operational. A faster build means a faster node start.
kernels.json as the Source of Truth
The original batch build pipeline used Falco’s kernel-crawler as its primary input. It scrapes distribution mirrors and produces a comprehensive list of every kernel version that exists across all supported distros — hundreds of entries per run. That gave us broad speculative coverage: we would precompile for kernels before any of our customers encountered them.
The problem is that most of those kernels never appear in any real fleet. Building for all of them up front costs significant CI time and runner capacity for variants that may never be needed.
We flipped the default: the nightly batch now reads from kernels.json instead of kernel-crawler.
When use_kernel_crawler is false, the matrix generator reads .github/kernels.json directly and builds only the kernels recorded there. The kernels.json is not written by hand. Every successful on-demand build appends the kernel it just compiled to the file via an automated PR. The result is a kernel list that reflects the kernels Riptides nodes have actually booted on — demand-driven rather than speculatively broad.
{
"x86_64": [
{
"target": "amazonlinux",
"kernelrelease": "6.12.58-82.121.amzn2023.x86_64",
"distroversion": "2023"
},
{
"target": "ubuntu",
"kernelrelease": "6.14.0-1021-gcp",
"distroversion": "24.04"
}
]
}The PR is created with a predictable branch name so concurrent builds for the same kernel do not open duplicates:
BRANCH="add-kernel/${DISTRIBUTION}/${ARCHITECTURE}/$(echo "${KERNELRELEASE}" | tr '.' '-')"
if git ls-remote --exit-code --heads origin "$BRANCH" > /dev/null 2>&1; then
echo "Branch $BRANCH already exists, skipping PR creation."
exit 0
fiThe flow is:
- A node boots on a kernel not in
kernels.json→ on-demand build triggers - Build completes → PR opens adding the kernel to
kernels.json - PR merges → nightly batch includes this kernel going forward
- Next node booting on the same kernel finds its driver prebuilt in GitHub Releases
The first node to encounter a new kernel pays the on-demand build latency. Every node after that finds the driver already available. kernels.json converges toward the actual kernel distribution of the fleet automatically.
kernel-crawler remains available as an opt-in (use_kernel_crawler: true), but we are not actively using it. The on-demand path combined with kernels.json covers everything the fleet actually needs.
Conclusion
The nightly batch and the on-demand path form a closed loop. On-demand handles kernels we have never seen; the batch rebuilds kernels we have, keeping drivers fresh as new driver versions ship. Together they ensure that a Riptides node can always load the right driver regardless of which kernel it finds at boot.
Key takeaways:
- Check for an existing artifact before dispatching any build — most on-demand requests will be served instantly from the existing prebuilt set.
- Use atomic check-and-reserve under a write lock to prevent duplicate workflow dispatches for concurrent requests.
- Build a Koji fallback chain (DNF → explicit URLs → Koji/CBS) so that kernels that have rolled off distribution mirrors remain buildable.
- Amazon Linux livepatch kernels are handled naturally by the on-demand path — no special discovery needed. If using kernel-crawler mode, extend its data with the livepatch CDN repository, as those kernels never appear in standard mirrors.
- Build on the same distro version as the target — cross-version builds may succeed but toolchain differences embed version-specific metadata that causes driver load errors at runtime.
- Prebuilt base images in GHCR eliminate public registry rate limits and cut per-build startup time, which directly reduces the time a node waits before its driver is ready.
- Default to a demand-driven kernel list over a speculative crawl — build what the fleet actually needs, not everything that exists.
Interested in how the batch build pipeline works? See our earlier posts:
- Building Linux Driver at Scale: Our Automated Multi-Distro, Multi-Arch Build Pipeline
- Beyond the Limits: Scaling Our Kernel Module Build Pipeline Even Further
If you enjoyed this post, follow us on LinkedIn and X for more updates. If you’d like to see Riptides in action, get in touch with us for a demo.
If you enjoyed this post, follow us on LinkedIn and X for more updates. If you'd like to see Riptides in action, get in touch with us for a demo.
Ready to secure your
workloads?
Kernel-level identity and enforcement. No code changes. Deploy in minutes.